프롬프트
텍스트를 음성으로 음성을 텍스트로 변환해 주는 프로그램을 만들어줘
ChatGPT 결과
이 프로그램은 음성을 텍스트로 변환하고, 텍스트를 음성으로 변환할 수 있어요.
- speech_recognition을 사용해 음성을 텍스트로 변환
- pyttsx3을 사용해 텍스트를 음성으로 변환
- 사용자가 원하는 기능을 선택할 수 있도록 인터페이스 제공
필요한 기능 추가나 수정이 있으면 알려주세요! 😊
코드
import speech_recognition as sr # 음성을 텍스트로 변환하는 모듈
import pyttsx3 # 텍스트를 음성으로 변환하는 모듈
def text_to_speech(text):
engine = pyttsx3.init() # 음성 합성 엔진 초기화
engine.say(text) # 텍스트를 음성으로 변환하여 출력
engine.runAndWait() # 음성 출력을 기다림
def speech_to_text():
recognizer = sr.Recognizer() # 음성 인식기 생성
with sr.Microphone() as source:
print("말하세요...")
recognizer.adjust_for_ambient_noise(source) # 주변 소음 조정
audio = recognizer.listen(source) # 음성 입력 받기
try:
text = recognizer.recognize_google(audio, language="ko-KR") # 음성을 텍스트로 변환
print("인식된 텍스트:", text)
return text
except sr.UnknownValueError:
print("음성을 인식할 수 없습니다.")
return None
except sr.RequestError:
print("음성 인식 서비스에 접근할 수 없습니다.")
return None
if __name__ == "__main__":
while True:
choice = input("텍스트를 음성으로 변환하려면 1, 음성을 텍스트로 변환하려면 2, 종료하려면 3을 입력하세요: ")
if choice == "1":
text = input("변환할 텍스트를 입력하세요: ")
text_to_speech(text)
elif choice == "2":
speech_to_text()
elif choice == "3":
print("프로그램을 종료합니다.")
break
else:
print("올바른 입력이 아닙니다. 다시 시도하세요.")
결과물
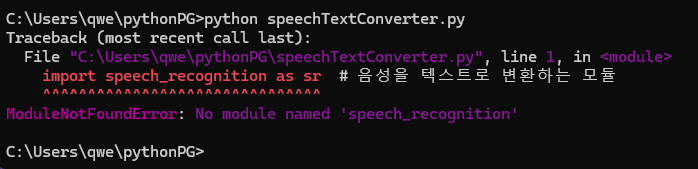
역시 모듈이 존재하지 않아 에러가 나는군요.
해결해 보겠습니다.
오류를 챗지피티에게 보여줍니다.
원인
오류의 원인은 speech_recognition 모듈이 설치되지 않았기 때문이에요.
아래 명령어를 실행해서 필요한 모듈을 설치한 후 다시 실행해 보세요.
해결 방법
- 모듈 설치
터미널(또는 명령 프롬프트)에서 아래 명령어를 입력하세요:- SpeechRecognition : 음성 인식 모듈
- pyttsx3 : 텍스트를 음성으로 변환하는 모듈
- pyaudio : 마이크 입력을 처리하는 모듈 (필요할 수도 있음)
-
sh복사편집pip install SpeechRecognition pyttsx3 pyaudio
- 설치 확인제대로 설치되었는지 확인할 수 있어요.
-
sh복사편집python -m pip show SpeechRecognition pyttsx3 pyaudio
- 실행 설치 후 다시 실행해 보세요! 🚀
혹시 pyaudio 설치 중 오류가 발생하면 추가 해결 방법을 알려줄 수 있어요. 😊
해결
C:\Users\qwe\pythonPG>pip install SpeechRecognition pyttsx3 pyaudio
Collecting SpeechRecognition
Downloading SpeechRecognition-3.14.1-py3-none-any.whl.metadata (31 kB)
Collecting pyttsx3
Downloading pyttsx3-2.98-py3-none-any.whl.metadata (3.8 kB)
Collecting pyaudio
Downloading PyAudio-0.2.14-cp313-cp313-win_amd64.whl.metadata (2.7 kB)
Collecting typing-extensions (from SpeechRecognition)
Downloading typing_extensions-4.12.2-py3-none-any.whl.metadata (3.0 kB)
Collecting standard-aifc (from SpeechRecognition)
Downloading standard_aifc-3.13.0-py3-none-any.whl.metadata (969 bytes)
Collecting audioop-lts (from SpeechRecognition)
Downloading audioop_lts-0.2.1-cp313-abi3-win_amd64.whl.metadata (1.7 kB)
Collecting comtypes (from pyttsx3)
Downloading comtypes-1.4.10-py3-none-any.whl.metadata (7.2 kB)
Collecting pypiwin32 (from pyttsx3)
Downloading pypiwin32-223-py3-none-any.whl.metadata (236 bytes)
Collecting pywin32 (from pyttsx3)
Downloading pywin32-309-cp313-cp313-win_amd64.whl.metadata (9.4 kB)
Collecting standard-chunk (from standard-aifc->SpeechRecognition)
Downloading standard_chunk-3.13.0-py3-none-any.whl.metadata (860 bytes)
Downloading SpeechRecognition-3.14.1-py3-none-any.whl (32.9 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 32.9/32.9 MB 82.1 MB/s eta 0:00:00
Downloading pyttsx3-2.98-py3-none-any.whl (34 kB)
Downloading PyAudio-0.2.14-cp313-cp313-win_amd64.whl (173 kB)
Downloading audioop_lts-0.2.1-cp313-abi3-win_amd64.whl (30 kB)
Downloading comtypes-1.4.10-py3-none-any.whl (241 kB)
Downloading pypiwin32-223-py3-none-any.whl (1.7 kB)
Downloading pywin32-309-cp313-cp313-win_amd64.whl (9.5 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 9.5/9.5 MB 99.1 MB/s eta 0:00:00
Downloading standard_aifc-3.13.0-py3-none-any.whl (10 kB)
Downloading typing_extensions-4.12.2-py3-none-any.whl (37 kB)
Downloading standard_chunk-3.13.0-py3-none-any.whl (4.9 kB)
Installing collected packages: standard-chunk, pywin32, pyaudio, typing-extensions, pypiwin32, comtypes, audioop-lts, standard-aifc, pyttsx3, SpeechRecognition
Successfully installed SpeechRecognition-3.14.1 audioop-lts-0.2.1 comtypes-1.4.10 pyaudio-0.2.14 pypiwin32-223 pyttsx3-2.98 pywin32-309 standard-aifc-3.13.0 standard-chunk-3.13.0 typing-extensions-4.12.2
[notice] A new release of pip is available: 24.3.1 -> 25.0.1
[notice] To update, run: python.exe -m pip install --upgrade pip
결과
실행해 본 결과 별문제 없이 실행되는 것을 확인할 수 있었습니다.


"텍스트를 음성으로 지원해 줍니다." 이게 스피커로 나왔고 제가 마이크에 말한 "말하세요"가 인식된 텍스트에 나오네요.
이런 걸 활용해서 개발한다면 한층 수준 높은 결과물이 나올 수 있겠습니다.
결과물을 동영상으로 만들고 싶어서 현재 어떻게 진행할지 고민 중입니다.
그럼 다음 개발로 다시 돌아오겠습니다. ^^
IT아재였습니다.
'IT정보 > AI프로그래밍' 카테고리의 다른 글
| 텍스트와 음성을 특정언어로 변환해주는 프로그램 만들기 (0) | 2025.03.16 |
|---|---|
| 프린트스크린샷 기능을 단축키로 변경해주는 프로그램 (0) | 2025.03.14 |
| 내컴퓨터 정보확인하는 프로그램 (0) | 2025.03.14 |
| QR코드를 만들어주는 프로그램 (0) | 2025.03.14 |
| 내부 외부 IP 확인하는 프로그램 만들기 (0) | 2025.03.13 |



